Kubernetes YAML syntax
https://betterprogramming.pub/understanding-kubernetes-yaml-syntax-83359d33f9c2
Key-values
multiple key-values
key1: value 1
key2: value 2
single key with map
key1:
subkey1: value 1
subkey1: value 2
subkey1: value 3
equivalent json for above
{
"key1": {
"subkey1": "subvalue1",
"subkey2": "subvalue2",
"subkey3": "subvalue3"
}
}
Lists
list:
- item1
- item2
- item3
- item4
- item5
equivalent json
{
"list": ["item1", "item2", "item3", "item4", "item5"]
}
List can contain multiple maps
list:
- item1
- mapItem1: value
mapItem2: value
- item3
- item4
- item5
equivalent json
[
"item1",
{
"mapItem1": "value",
"mapItem2": "value"
},
"item3",
"item4",
"item5"
]
Example deployment.yaml
spec:
selector:
matchLabels:
app: nginx
equivalent json
"spec": {
"selector": {
"matchLabels": {
"app": "nginx"
}
}
}
Another yaml with lists
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
json equivalent
"spec": {
"containers": [
{
"name": "nginx",
"image": "nginx:1.7.9",
"ports": [
{
"containerPort": 80
}
]
}
]
}
Required Arguments in Kubernetes YAML
- apiVersion
- kind
- metadata
- spec
apiVersion - “Which version of the Kubernetes API you’re using to create this object?”
kind - “what kind of object are you creating?”
metadata - Data that helps uniquely identify the object, including a
namestring,UID, and optionalnamespace
Example deployment.yaml
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
Converted json file
{
"apiVersion": "apps/v1",
"kind": "Deployment",
"metadata": {
"name": "nginx-deployment"
},
"spec": {
"selector": {
"matchLabels": {
"app": "nginx"
}
},
"replicas": 2,
"template": {
"metadata": {
"labels": {
"app": "nginx"
}
},
"spec": {
"containers": [
{
"name": "nginx",
"image": "nginx:1.7.9",
"ports": [
{
"containerPort": 80
}
]
}
]
}
}
}
}
Each object has unique name and every kubernetes object has unique id across whole cluster.
You can have 1 pod named myapp-1234 within same namespace but you can have one Pod and one Deployment that are each named myapp-1234
Names
A client-provided string that refers to an object in a resource URL, such as /api/v1/pods/some-name.
Only one object of a given kind can have a given name at a time. However, if you delete the object, you can make a new object with the same name.
Names must be unique across all API versions of the same resource. API resources are distinguished by their API group, resource type, namespace (for namespaced resources), and name. In other words, API version is irrelevant in this context.
Naming convections with length restrictions and character limits are mentioned here https://kubernetes.io/docs/concepts/overview/working-with-objects/names/
Labels and Selectors
Labels are key-value pairs attached to objects such as pods. They are used to specify attributes of objects meaningful and relevant to users.
"metadata": {
"labels": {
"key1" : "value1",
"key2" : "value2"
}
}
Use case: Labels enable users to map their own organizational structures onto system objects in a loosely coupled fashion, without requiring clients to store these mappings.

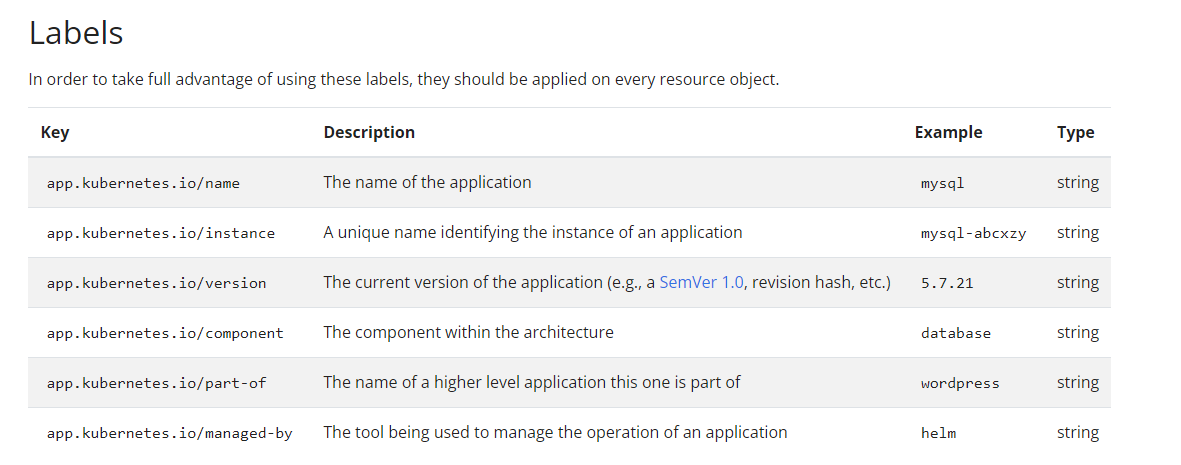
Recommended Labels
See examples here - https://kubernetes.io/docs/concepts/overview/working-with-objects/common-labels/
Namespaces
In Kubernetes, namespaces provides a mechanism for isolating groups of resources within a single cluster. Names of resources need to be unique within a namespace, but not across namespaces.
Namespaces cannot be nested inside one another and each Kubernetes resource can only be in one namespace.
Namespaces are a way to divide cluster resources between multiple users

Not all objects are in namespace. Low level resources such as nodes and persistentVolumes are not in any namespace.
Annotations
These are arbitrary non-identifying metadata to objects. Annotations, like labels, are key/value maps:
"metadata": {
"annotations": {
"key1" : "value1",
"key2" : "value2"
}
}
Field Selectors
Field selectors let you select Kubernetes objects based on the value of one or more resource fields. Here are some examples of field selector queries:
metadata.name=my-servicemetadata.namespace!=defaultstatus.phase=Pending
example - kubectl get pods --field-selector status.phase=Running
It supports operators - =, !=, ==
kubectl get services --all-namespaces --field-selector metadata.namespace!=default
Chained Selectors - kubectl get pods --field-selector=status.phase!=Running,spec.restartPolicy=Always
Finalizers
Finalizers are namespaced keys that tell Kubernetes to wait until specific conditions are met before it fully deletes resources marked for deletion. Finalizers alert controllers to clean up resources the deleted object owned. When you attempt delete, -
- Modifies the object to add a
metadata.deletionTimestampfield with the time you started the deletion. - Prevents the object from being removed until its
metadata.finalizersfield is empty. - Returns a 202 status code (HTTP “Accepted”)
Owners and Dependents
Some objects are owners of other objects such as ReplicaSet is owner of pods. These owned objects are dependents of their owner.
Ownership is different from labels/selectors. Services uses labels to allow control pane to determine EndpointSlice objects for that service. Each EndpointSlice has owner reference. Owner references help different parts of Kubernetes avoid interfering with objects they don’t control.