Aim
Design, develop and deploy a working url shortener service which is able to handle huge number of requests and processing with high availability and fault tolerance. Best code practices have to be followed with optimisations made on asynchronous implementation, tests, max retries, high availability etc
We start with building a local app to be deployed on docker with mongodb and redis running locally or on docker. This will then be shifted to kubernetes cluster once it works with tests.
The code has been uploaded here - https://github.com/VarunArora14/url-shortener-system-design
Docker Workflow Diagram
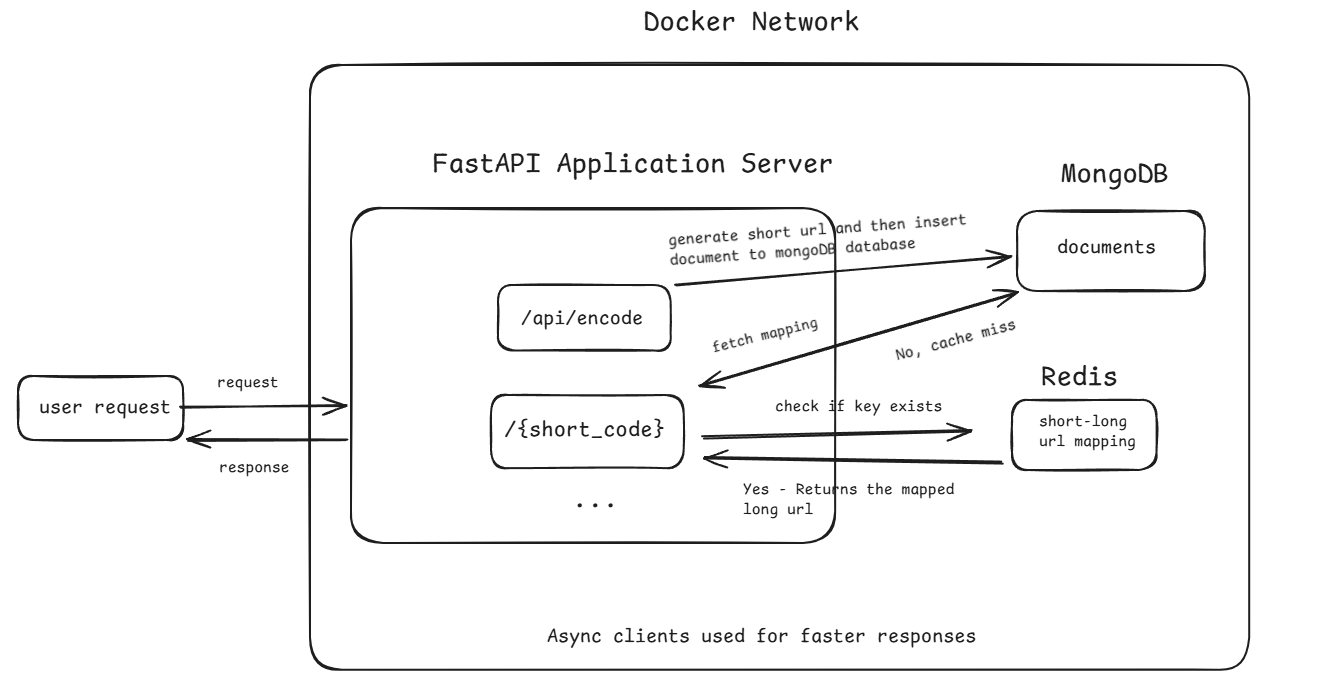
The code is for implementing a url shortener service with async API calls being used as well as synchronous code implementation as part of synchronous_app/app.py.
The aim of this project is to implement and understand real world system design constraints and problems that we wish to solve.
In order to run the code via docker compose, run command docker-compose up --build to build the service and mongo container in same network.
For just running the app, run python fapp.py. Make sure that IS_LOCAL values is set to True in the .env file in the same folder directory as fapp.py
Important API endpoints:
/- returns home page json/health- health check of API and database/api/encode- Post endpoint expecting data in format{long_url: 'url'}/{short_code}- Redirects the existing site to the mapped url as in database./api/list- List all the url mappings of long to short urls/docs- Swagger documentation of above APIs
The way it works is that if my base url is http://localhost:5000, then I save the short url in format http://localhost:5000/{short_code} which then handles the routing to the actual mapped url.
System Design Choices -
- MongoDB has been used as database to store long-short url mappings as it scales out via horizontal scaling and is much more resilient than SQL based databases especially during high throughput(NoSQL has much higher throughput while SQL has transactional accuracy). SQL databases will encounter performance issues for large amount of data (non transactional) especially if need horizontal scaling. Vertical scaling will be much more expensive for large scale. Another reason is high availability of NoSQL databases via data replication and fault toleration via master-slave node cluster setup.
- Redis is a great choice for storing most common urls as it can avoid DB searches for mappings of short urls. LRU or some other key eviction policy must be set with proper cluster/standalone config for cache eviction.
- FastAPI as application server has been used to handle async requests with respective async libraries being used for handling large number of requests. This will be then deployed on k8s with with multiple instances (load balanced with
serviceusing round robin)
Other Implementation choices -
Use of random code generator over hash + base64 encode of url for short url creation has been done as if we use hash with encoding, while we get a unique id for each url, collision resolution for this won’t be easy. It is better to generate random urls => check their occurence and then store them.
In redis fetch of all key-value pairs as part of API, I used
scan()method and notkeys()method as for a larger number of key-val pairs, the method blocks the server while thescan()method brings pagination giving few results at a time maintaining cursor position as well. Note that cursor is index to the iterator which scan command updates for subsequent calls (same as next page for pagination). Thescanmethod works with user initialisingcursorto 0 and ends when the server returns a cursor of 0. It works by updating cursor with each call and return to user for next iteration step. We usescan_iterabstraction by redis-py package that abstracts away cursor management and directly provides python iterator for easier loops. This method is superior toKEYSwhich has blocking code and blocks IO operations till scaling** and is much more resilient than SQL-based databases, especially during high throughput (NoSQL has much higher throughput while SQL has transactional accuracy). SQL databases will encounter performance issues with large amounts of data (non-transactional), especially if horizontal scaling is needed. Vertical scaling will be much more expensive for large scale. Another reason is the **high availability** of NoSQL databases via data replication and fault tolerance through a master-slave node cluster setup.Redis is a great choice for storing the most common URLs as it can avoid DB searches for mappings of short URLs. An LRU or some other key eviction policy must be set with proper cluster/standalone configuration for cache eviction.
FastAPI as an application server has been used to handle async requests with respective async libraries being used for handling a large number of requests. This will then be deployed on k8s with multiple instances (load balanced with
serviceusing round-robin).
Other Implementation Choices:
- The use of a random code generator over hash + base64 encode of URL for short URL creation has been done because if we use hash with encoding, while we get a unique ID for each URL, collision resolution for this won’t be easy. It is better to generate random URLs, check their occurrence, and then store them.
- In Redis, for fetching all key-value pairs as part of the API, I used the
scan()method and not thekeys()method because for a larger number of key-value pairs, thekeys()method blocks the server while thescan()method brings pagination, giving a few results at a time and maintaining cursor position as well. Note that the cursor is an index to the iterator which the scan command updates for subsequent calls (same as the next page for pagination). Thescanmethod works with the user initializingcursorto 0 and ends when the server returns a cursor of 0. It works by updating the cursor with each call and returning it to the user for the next iteration step. We use thescan_iterabstraction by the redis-py package that abstracts away cursor management and directly provides a Python iterator for easier loops. This method is superior toKEYSwhich has blocking code and blocks IO operations until the processing is complete. - The DB connections for Redis and MongoDB are stored inside the FastAPI app state as part of best practice, providing an async context manager for managing the lifecycle of the FastAPI app. This context manager allows managing resources that need to be set up before the application starts and cleaned up after the application stops.
Redis scan_iter implementation:
pairs = {}
try:
# Provide proper match and batch size as small batch size means slow execution as all batch keys come at a time with cursor managed by redis-py. This method has to be async.
async for key in app.state.redis.scan_iter(match="*", count=batch_size):
value = await app.state.redis.get(key)
pairs[key] = value
return pairs
except redis.RedisError as e:
# Handle the error
pass
except Exception as e:
return {"error": str(e)}
Redis commands -
- Inside redis docker container run command
redis-clito connect - Run command
pingto confirm - Command
keys *to get all keys - command
get <keyname>to get the corresponding value of the<keyname> - command
set <k> <v>to set key-value pairs
Additional things found as part of learning -
- Run command
fastapi dev <app.py>for running dev server when uvicorn server is not used - If uvicorn is being used, provide the name of the file which represents the app as
uvicorn.run("myapp:app",..)wheremyappis themyapp.pycontaining your code - If you have made code changes and your uvicorn server is not having those changes, go to your task manager or do
ls(for linux) and find programs whose name havepython.exein them and do end task on them. For linux, kill their task PID bytaskkill /PID <PID> /F(force kill pid) - If you have MongoDB running both locally and on docker at same port 27017 and have docker port exposed to same port as well, then if you make request to
127.0.0.1:27017then the request will go to the local DB and NOT the docker container. In docker-compose in windows, it uses docker internal network for requests. For internal networking, the host url changes from mongodb://localhost:27017 to mongodb://mongo:27017 (mongo is the container name and so this host). Note - this is without the credentials which should be configured as well. For accessing the container mongodb from outside, change the host-container port mapping asm-compose.ymlfile. - For making requests to other containers running in same docker internal network, use their container name as the hostname for automatic DNS resolution for container names. If the container name is mongo2 then conn url is
mongodb://mongo2:27017. Similarly, if for redis the container name is redis, then it’s conn url isredis://redis:6379/0. Refer to the format -redis://[:password]@host:port[/db_number]. For local redis, it will beredis://localhost:6379/0. Refer to redis-py documentation for more asyncio - https://redis-py.readthedocs.io/en/stable/examples/asyncio_examples.html
Ideal URL Shortener System Design
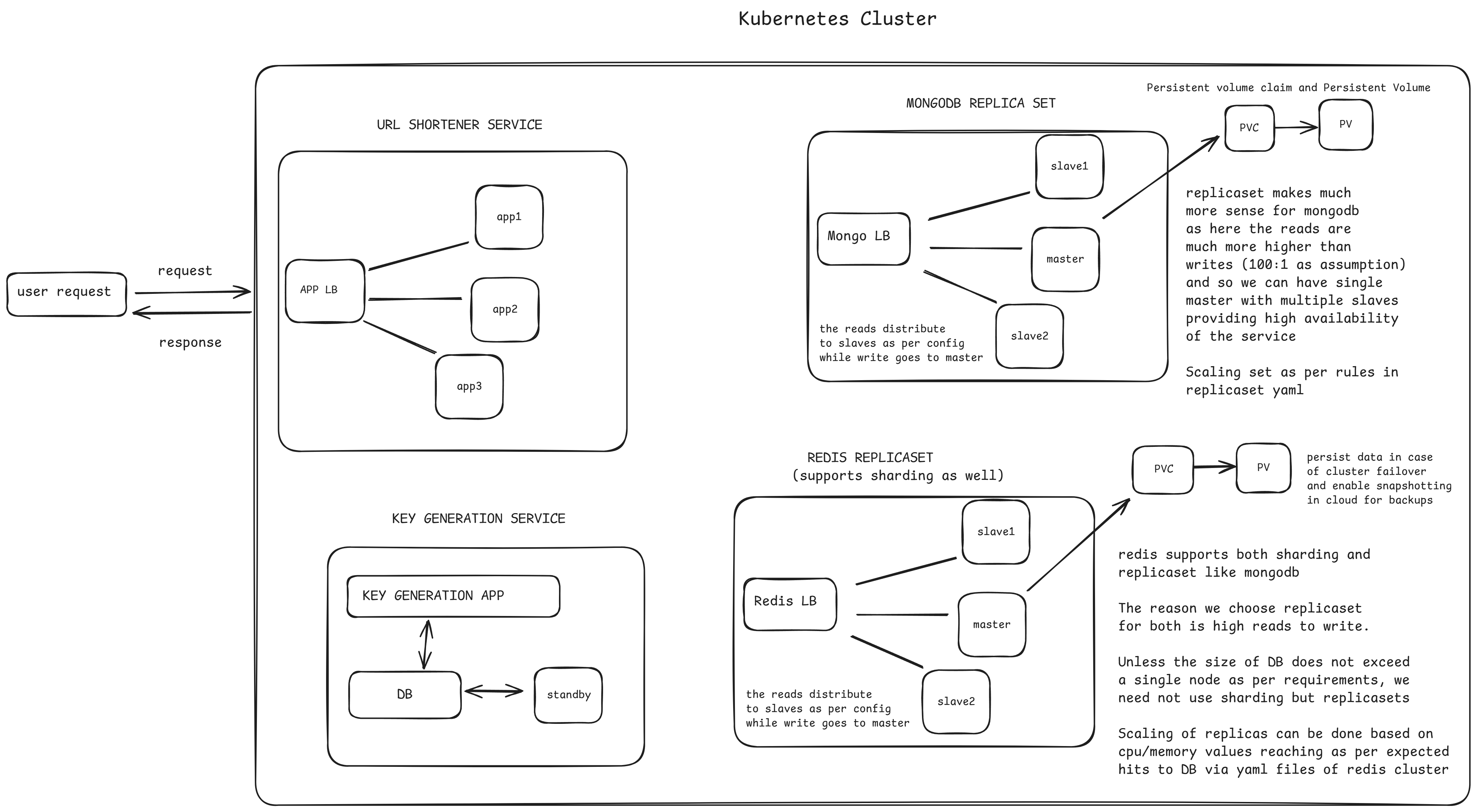
In order to get closer to this, the next steps will be to upload the service to k8s and then the databases in their clusters, managed by their yaml files and config files. Looking at the tests notes created so far -
Testing Url Shortener Service
This project uses the pytest framework along with the pytest-asyncio plugin. The code -
@pytest.fixture(scope="module")
async def test_app():
app.dependency_overrides = {}
# Using async with for proper handling of the AsyncClient instance
async with AsyncClient(app=app, base_url="http://localhost:5000") as ac:
yield ac # Yield the client to the test
This sets up an instance of your app. It overrides existing connections or external APIs to clear test environments and creates a test Async client to simulate HTTP requests to the FastAPI app. The test client ac is then yielded to be used in test functions.
Important - Setting scope="module" in the @pytest.fixture ensures that the event loop remains active for all test cases within the module. Without this, the event loop may end prematurely, causing errors. Using scope="session" resulted in errors, but setting it to scope="module" resolved the issue by keeping the event loop active until all tests in the module are completed.
Note - The event loop scope for asynchronous fixtures will default to the fixture caching scope. Future versions of pytest-asyncio will default the loop scope for asynchronous fixtures to function scope. Set the default fixture loop scope explicitly in order to avoid unexpected behavior in the future. Valid fixture loop scopes are: “function”, “class”, “module”, “package”, “session”
Then we create another fixture to setup DB for the app state -
@pytest.fixture(scope="module")
async def setup_test_db():
# Setup MongoDB and Redis for testing
app.state.client = AsyncIOMotorClient("mongodb://localhost:27017")
app.state.db = app.state.client.test_db
app.state.collection = app.state.db.test_collection
app.state.redis = redis.from_url("redis://localhost:6379")
yield
We define test cases via @pytest.mark.anyio.
We initialize the clients for each test (note that the fixtures themselves do not use await) and their implementation will consist of async-await methods.
@pytest.mark.anyio
async def test_mong_redis(test_app, setup_test_db):
mongodb_ping = await app.state.db.client.admin.command("ping")
redis_ping = await app.state.redis.ping()
assert mongodb_ping == {'ok': 1.0}
assert redis_ping == True
The reason we changed @pytest.mark.asyncio to @pytest.mark.anyio was that in the former, the httpx app client was returning async_generator() and not the actual client.
Refer to other solution using @pytest_asyncio.fixture here - https://stackoverflow.com/questions/72996818/attributeerror-in-pytest-with-asyncio-after-include-code-in-fixtures
Also, with anyio, you can use other concurrency packages like asyncio and trio for tests and APIs.
The tests are added automatically based on assert in the code -
assert response.status_code == 200
assert response.json() == {"message":"Home page"}
Tests Hierarchy Issues
Current Hierarchy
project/
│
├── fapp.py
└── tests/
└── test_fapp.py
To resolve import path issues when the tests folder needs to import fapp.py from the parent directory, add the following code:
import sys
sys.path.append('../')
This modifies the python import path so python will look into that directory (parent in this case) when searching modules (fapp imported as module). This was done because the module or script is not in the same folder but higher or lower in the hierarchy.
This concludes the part 1 of this blog. The next blog will feature notes and implementation of deploying it on kubernetes and next steps to deploy this on actual cloud provider like AWS without localhost re-routing.